 Dutch Data Dude
Dutch Data DudeWorking with aggregations in Power BI Desktop
23 Apr 2020One of the first things I did after joining the Power BI Desktop team is catching up to reality - the speed of innovation in this team is amazing and I had a lot of reading to do. One of the first things on my list were aggregations.
Aggregations bring me back to the good old SSAS Multidimensional days. The days that I invariably built the aggregations tree the wrong way around, SSAS would complain, I would scream and eventually give in.
You can imagine that I was curious but skeptical when I tried aggregations in Power BI Desktop. I was afraid of ending up in the same hate-but-need relationship that I had with SSAS multidimensional when it came to aggregations.
The good news? It is not like that. At all. Once you have aggregations working, they are great.
The not so good news? It took me longer than I am willing to admit getting them working - primarily due to data types and creation of the aggregated table. More details in this blog post.
Why care about aggregations?
I see aggregations as pre-calculations - you identify datasets that you would need to return often and by pre-calculating the results and storing them performance is improved, resulting in a better end-user experience. The difference is dramatic, especially when dealing with big data. If the detail table you are aggregating over contains billions of rows and your aggregation table just mere millions, you and your users will benefit greatly. You leave your source in DirectQuery mode so you are not importing the huge table to Power BI and create the aggregation table in Import mode so it is included in the Power BI data model.
Setting up aggregations
The documentation explains about everything there is to know about aggregations in Power BI Desktop. I suggest you read it before reading on. The devil, however, is in the detail, specifically with data types and creating the aggregation table itself. The documentation expects you to know how to create the aggregation table. I will explain how I did it later in this blog post.
Data types
First, the biggest problem I faced when working with aggregations: data types. Check your data types and check them again. Whenever you cannot select your detail column in the 'Manage Aggregations' screen you probably have a data type mismatch between the Aggregation Column and the Detail Column. I had, every time I ran into trouble here.
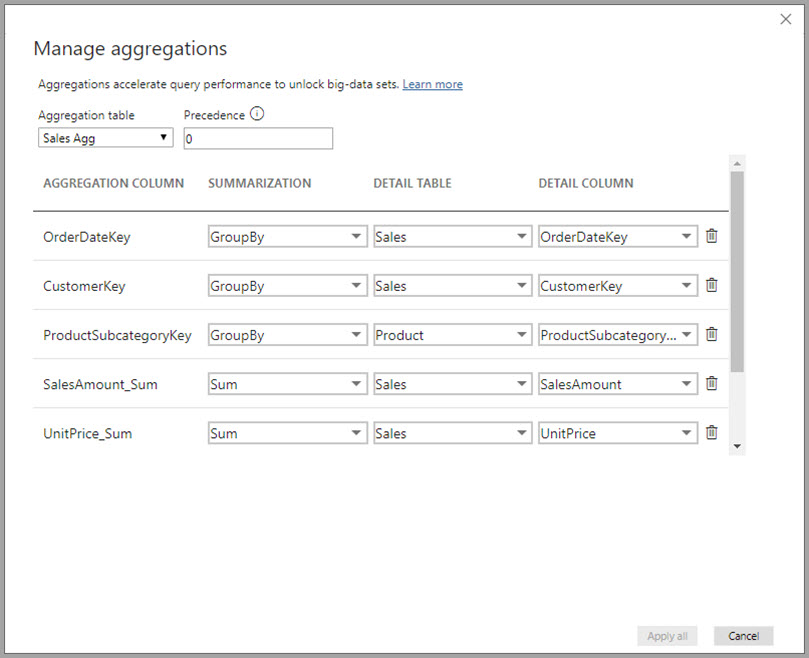
Creating the aggregation table
Creating the aggregation table can either be done by writing a query against the source doing a group by or something equivalent or doing that in PowerQuery. I chose the last option and it was simple if you remember to include all the metrics you want included in your aggregations (duh) as well as any dimension column! It is not enough to just include the key to your date table if you want the aggregation to work on Month or Year level. You will have to include those levels as well (just like in SSAS multidimensional).
Using the AdventureWorks sample DWH I created an aggregation table that summarizes SalesAmount from FactInternetSales by product category, product subcategory, productname, month, quarter, and year and includes a row count.
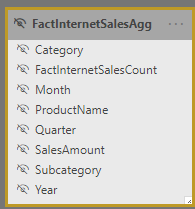
The quick-and-dirty PowerQuery query for this is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
let
Source = Sql.Databases(myserver),
AdventureWorksDW2017 = Source{[Name="AdventureWorksDW2017"]}[Data],
dbo_FactInternetSales = AdventureWorksDW2017{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Expanded DimDate(OrderDateKey)" = Table.ExpandRecordColumn(dbo_FactInternetSales, "DimDate(OrderDateKey)", {"EnglishMonthName", "CalendarQuarter", "CalendarYear"}, {"DimDate(OrderDateKey).EnglishMonthName", "DimDate(OrderDateKey).CalendarQuarter", "DimDate(OrderDateKey).CalendarYear"}),
#"Expanded DimProduct" = Table.ExpandRecordColumn(#"Expanded DimDate(OrderDateKey)", "DimProduct", {"EnglishProductName", "DimProductSubcategory"}, {"DimProduct.EnglishProductName", "DimProduct.DimProductSubcategory"}),
#"Renamed Columns" = Table.RenameColumns(#"Expanded DimProduct",{{"DimProduct.EnglishProductName", "ProductName"}}),
#"Expanded DimProduct.DimProductSubcategory" = Table.ExpandRecordColumn(#"Renamed Columns", "DimProduct.DimProductSubcategory", {"EnglishProductSubcategoryName", "DimProductCategory"}, {"DimProduct.DimProductSubcategory.EnglishProductSubcategoryName", "DimProduct.DimProductSubcategory.DimProductCategory"}),
#"Renamed Columns1" = Table.RenameColumns(#"Expanded DimProduct.DimProductSubcategory",{{"DimProduct.DimProductSubcategory.EnglishProductSubcategoryName", "Subcategory"}}),
#"Expanded DimProduct.DimProductSubcategory.DimProductCategory" = Table.ExpandRecordColumn(#"Renamed Columns1", "DimProduct.DimProductSubcategory.DimProductCategory", {"EnglishProductCategoryName"}, {"EnglishProductCategoryName"}),
#"Renamed Columns2" = Table.RenameColumns(#"Expanded DimProduct.DimProductSubcategory.DimProductCategory",{{"EnglishProductCategoryName", "Category"}}),
#"Grouped Rows" = Table.Group(#"Renamed Columns2", {"DimDate(OrderDateKey).CalendarYear", "ProductName", "Subcategory", "Category", "DimDate(OrderDateKey).CalendarQuarter", "DimDate(OrderDateKey).EnglishMonthName"}, {{"FactInternetSalesCount", each Table.RowCount(_), type number}, {"SalesAmount.1", each List.Sum([SalesAmount]), type number}}),
#"Changed Type" = Table.TransformColumnTypes(#"Grouped Rows",{{"FactInternetSalesCount", Int64.Type}, {"SalesAmount.1", type number}}),
#"Renamed Columns3" = Table.RenameColumns(#"Changed Type",{{"SalesAmount.1", "SalesAmount"}, {"DimDate(OrderDateKey).CalendarQuarter", "Quarter"}, {"DimDate(OrderDateKey).EnglishMonthName", "Month"}, {"DimDate(OrderDateKey).CalendarYear", "Year"}})
in
#"Renamed Columns3"
Creating the aggregations
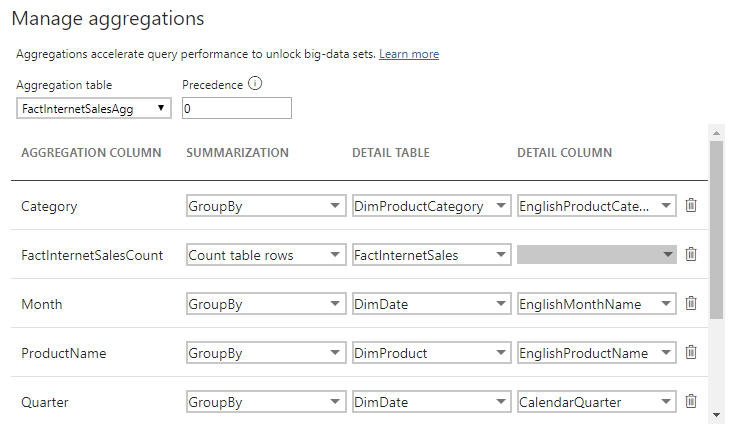
Once you have your aggregation table created, right click on it and choose Manage aggregations. You can also click the table you are aggregating (FactInternetSales in my example) but then you will have to manually select the Aggregation table.
This is how I set it up:
| Aggregation column | Summarization | Detail table | Detail column |
| Category | GroupBy | DimProductCategory | EnglishProductCategoryName |
| FactInternetSalesCount | Count table rows | FactInternetSales | N/A |
| Month | GroupBy | DimDate | EnglishMonthName |
| ProductName | GroupBy | DimProduct | EnglishProductName |
| Quarter | GroupBy | DimDate | CalendarQuarter |
| SalesAmount | Sum | FactInternetSales | SalesAmount |
| Subcategory | GroupBy | DimProductSubcategory | EnglishProductSubcategoryName |
| Year | GroupBy | DimDate | CalendarYear |
The biggest problem I faced when working with aggregations: data types. Check your data types and check them again.
Testing your aggregations
To check your aggregation table makes sense you can create two measures as follows:
FactInternetSalesAggRowCount = COUNTROWS(FactInternetSalesAgg) FactInternetSalesRowCount = COUNTROWS(FactInternetSales)
In my sample I got from 60k rows in FactInternetSales (detail table) to 2k in FactInternetSalesAgg (aggregated table). Of course, I know 60k rows is not enough to warrant the use of aggregations in the first place.
To test if the aggregations work as expected, you can connect SQL Profiler to the diagnostics port of Power BI Desktop - to get the port, run the following command in an elevated prompt and look for the port used by msmdsrv.exe:
netstat -b -n
In SQL profiler, connect to Analysis Services and use localhost:[port recorded earlier] to start the trace. You should be tracing these events:
- Queries Events\Query Begin
- Query Processing\Vertipaq SE Query Begin
- Query Processing\DirectQuery Begin
- Query Processing\Aggregate Table Rewrite Query
Whenever your aggregations are used you will see the Vertipaq SE Query Begin event and whenever your aggregations are missed you will see DirectQuery Begin.
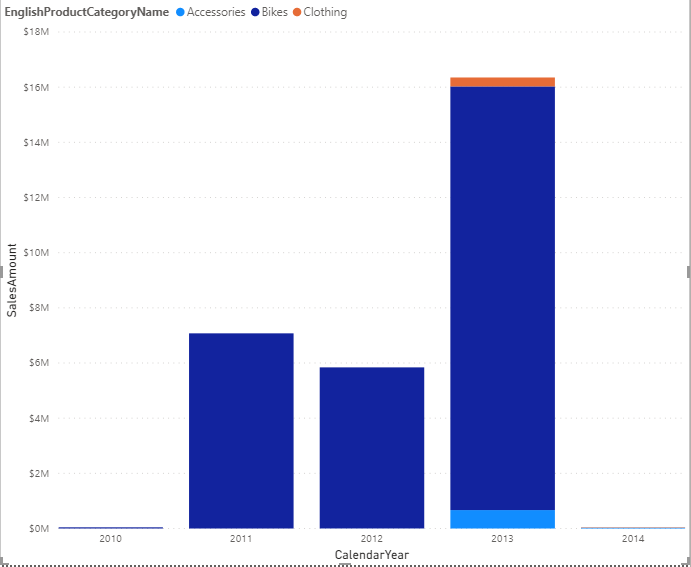
I made a column chart that includes SalesAmount for ProductCategory per CalendarYear, CalendarQuarter, EnglishMonthName and DateKey. Using the drill-down feature and keeping a close eye on the SQL Profiler I was able to verify that the aggregation worked for all of the levels in the drilldown except the DateKey, as it was not included in the aggregation table. See the images below. Rest assured, even if you did not include the granularity of the data in your aggregation table, you will get a result since Power BI will 'just' query the original data source.
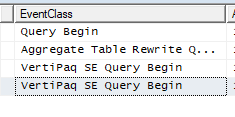
Query hitting the aggregation table
See below for a graph and trace that hit the aggregation table. Notice the VertiPaq SE Query Begin event.
Query not using the aggregation table
See below for a graph and trace that does not use the aggregation table. Notice the DirectQuery Begin event.
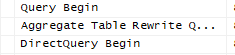
It turns out the aggregations are working just fine. I hope this was helpful, let me know if you have any questions and ideas!
